本文将介绍小样本学习中的N-way K-shot.
0 简介
小样本学习(few-shot learning)的提出是基于这个事实:人类可以只看过很少的样本,就能识别出新的实体,但机器需要学习大量的样本. 小样本学习的目标是在只见过每个类别中少量的训练样本后,就能分类新的数据. 特别地,one-shot learning指每个类别只有1个样本,zero-shot learning指最终需要分类的数据类别在训练过程中没有出现.
1 N-Way K-Shot
小样本学习实际上是元学习(meta-learning)的思想,即学习如何学习. 所以,每次训练(episode)都会采样得到不同的元任务(meta-task),然后进行进行N-way K-shot分类. 与其它分类任务不同的是,训练和测试阶段各自有支持集(support set)与查询集(query set),后者用于评估该任务. 可以将小样本学习理解为让模型学习如何根据从support set中学习到的内容来预测query set.
N-way指分类时的类别数,而K-shot指每个类别的样本数. 这里以一个3-way 2-shot的图像分类任务为例.
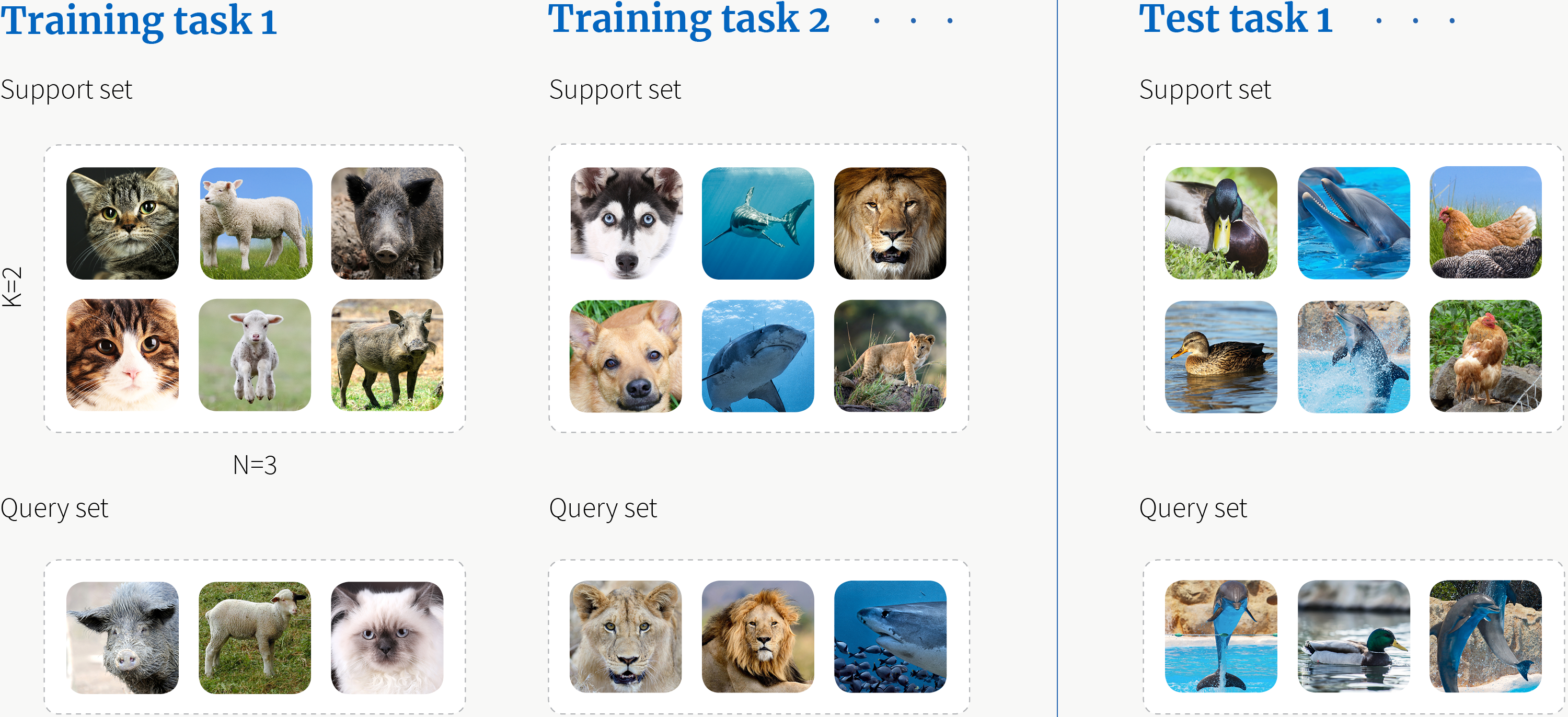
值得注意的是:
- 每个training task之间的类别互不相交.
- 训练集与测试集之间的类别互不相交.
2 训练
采样
显然,在每次training task的训练中,采样并不是一件易事. 尤其是lexical级别分类的自然语言处理任务(例如NER). 采样也有一些方法,这里暂时不展开叙述.
损失函数
通常定义为query set在该training meta-task上的损失.
参考
[1] BOREALIS AI